Đây là một hướng dẫn sơ lược về cách đặt tên nhiều loại đối tượng khác nhau, bạn có thể tham khảo để tổ chức data warehouse của mình cho gọn gàng và dễ kiểm soát, đặc biệt là khi số lượng bảng, data pipeline, transformation tăng lên nhiều.
Đặt tên data pipeline
- Bản có thể dùng format Load [tên nguồn] to [tên destination], có thể thêm tên team quản lý vào nếu trong công ty của bạn có nhiều team cùng có thể tạo data connection / pipeline trên Elton Data. Bạn càng đặt tên chi tiết, nhiều thông tin thì khi bạn tìm kiếm sẽ càng dễ dàng.
Tổ chức bảng trong data warehouse
- Trong data warehouse nói riêng và các loại database nói chung, data thường sẽ tổ chức theo 3 cấp độ: project > schema / dataset > bảng
- Tên dataset nên viết thường, và sử dụng cơ chế gạch dưới để dễ đọc. Ví dụ: facebook_ads_dwh, sales_datamart, social_datamart
- Tên bảng chắc chắn nên viết thường, và cũng sử dụng cơ chế gạch dưới để dễ đọc. Đừng lo tên bảng quá dài, một tên bảng dài mà dễ hiểu thì vẫn tốt hơn là tên bảng viết tắt nhưng nhiều người không hiểu hoặc dễ hiểu lầm. Ví dụ: facebook_ads_campaign_data_flatten
Tổ chức datamart
Datamart là các dataset dùng để chứa những bảng dữ liệu đã được chuẩn bị, làm sạch, lọc… và sẵn sàng để sử dụng. Đặc biệt các bảng mà các team BI, team analyst, team business truy xuất thì nên được chuẩn bị sẵn sàng và lưu trữ vào các datamart, như vậy sẽ dễ dàng cho họ khi kéo thả số liệu thay vì phải đi viết lại SQL từ đầu, vốn có thể sai sót và bị trùng lặp. Bạn có thể dùng tính năng transformation của Elton Data để xây dựng các datamart.
Datamart nên phân cấp theo mức độ sử dụng, ở các công ty quy mô vừa và nhỏ thường sẽ được phân theo mục đích hoặc phòng bạn sử dụng. Một số công ty sẽ phân theo miền kiến thức. Việc tổ chức này hoàn toàn phụ thuộc vào ý muốn và cách triển khai của bạn, không có một con đường cố định nào cả.
Ví dụ, các bảng mà đội sales, kinh doanh cần sử dụng và liên quan tới bán hàng thì sẽ nằm ở sales_datamart, còn những dữ liệu mà team vận hành cần dùng có thể sẽ nằm ở ops_datamart.
Việc phân chia datamart như thế này sẽ giúp phân quyền truy cập hiệu quả và quản lý dễ dàng, bạn có thể biết được dữ liệu nào nằm ở đâu.
Nhớ dùng partition
Partition là một tính năng của BigQuery nói riêng và các data warehouse nói chung để giúp “phân chia” data, lợi ích của việc sử dụng partition là khi truy vấn sẽ nhanh hơn và tốn ít chi phí hơn. Đôi khi chỉ việc partition bảng và chỉnh lại câu query WHERE thôi mà bạn đã có thể tiết kiệm được rất nhiều tiền khi sử dụng các hệ thống cloud data warehouse.
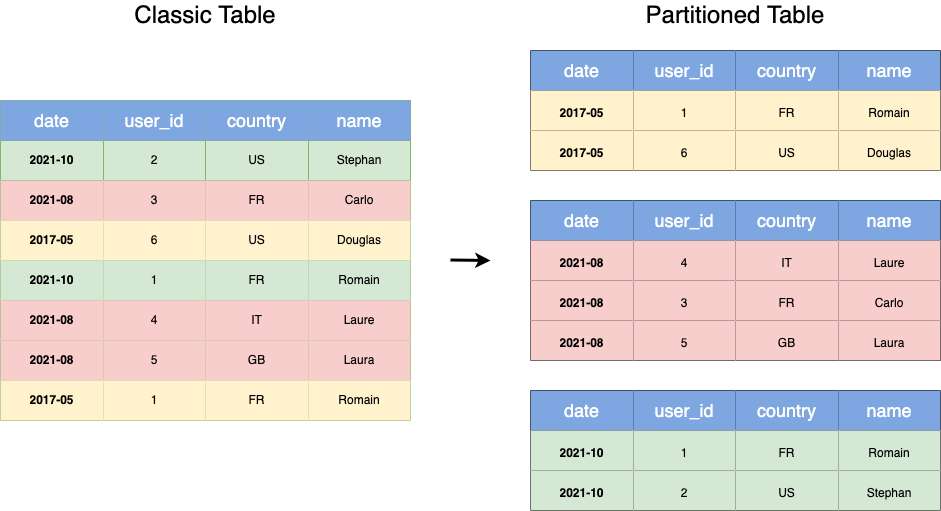
Nguồn: Toward Data Science
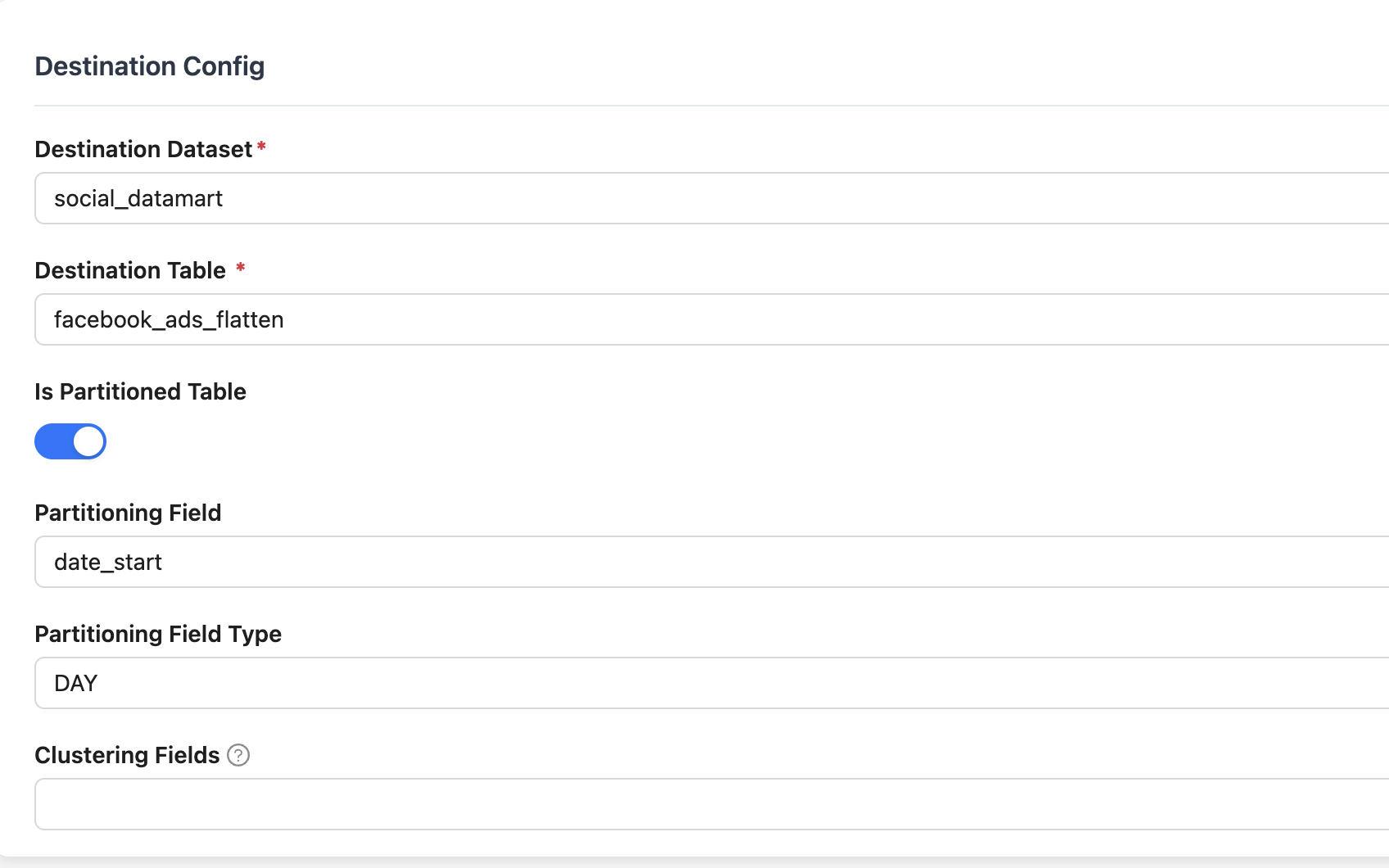
Nếu bạn tạo bảng bằng tính năng Transformation của Elton Data, bạn có thể cấu hình cột partition như hình bên dưới. Chọn cột ở Partition Field, và chọn loại data trong cột dùng để partition là ngày, tháng, giờ hay năm. Đa số tình huống sử dụng thông thường bạn sẽ cần chọn DAY vì partition theo ngày là tiện và dễ hiểu. Một số trường hợp đặc biệt bạn có thể điều chỉnh lại tùy theo dữ liệu và nhu cầu của mình.