

Đa số khách hàng của Elton sử dụng Google BigQuery (BQ) làm data warehouse, bản thân 3 công ty trước đó mình làm cũng dùng BQ cho mục đích này, nên mình cũng có được vài kinh nghiệm nhỏ trong việc tối ưu vận hành cũng như tiết kiệm chi phí khi sử dụng. Mình chia sẻ với mọi người để nếu ai đang dùng BigQuery có thể tham khảo nhé.
Sử dụng partition cho các bảng lớn
Partition (phân vùng) trong BigQuery là một kỹ thuật giúp chia một bảng lớn thành các phân vùng nhỏ hơn, dễ quản lý hơn. Mỗi phân vùng được tạo ra dựa trên một cột khóa, thường là cột ngày tháng năm. Khi bạn truy vấn dữ liệu, thay vì phải quét toàn bộ bảng, BigQuery chỉ cần quét các phân vùng chứa dữ liệu bạn cần.
Ví dụ, nếu bạn có một bảng giao dịch hàng ngày, bạn có thể phân vùng bảng đó theo cột ngay_tao_don_hang. Khi bạn muốn xem dữ liệu của tháng 10 năm 2024, câu lệnh
1WHERE ngay_tao_don_hang BETWEEN '2024-10-01' AND '2024-10-31'sẽ chỉ quét dữ liệu trong phân vùng của tháng 10, thay vì quét qua toàn bộ lịch sử dữ liệu của bảng. Điều này không chỉ giúp giảm đáng kể chi phí mà còn trả về kết quả nhanh hơn rất nhiều.
Partition thường được dùng với các cột ngày tháng năm mà bạn hay dùng để chặn ngày trên báo cáo, ví dụ như ngay_tao_don_hang, ngay_nhap_kho_san_pham, ngay_dang_ky_thanh_vien...
Không SELECT *, chỉ chọn các cột bạn cần
Đây là một trong những quy tắc cơ bản nhất để tiết kiệm chi phí trong BigQuery. BigQuery tính phí dựa trên lượng dữ liệu mà bạn quét. Khi bạn sử dụng SELECT *, hệ thống sẽ quét toàn bộ dữ liệu của tất cả các cột trong bảng, bất kể bạn có cần chúng hay không.
Thay vào đó, trong các câu truy vấn thông thường, bạn hãy luôn liệt kê rõ ràng các cột mà bạn thực sự cần. Việc này không chỉ giảm chi phí vì lượng dữ liệu quét ít hơn mà còn giúp truy vấn của bạn chạy nhanh hơn, vì hệ thống không phải xử lý những dữ liệu không cần thiết.
Tuy nhiên, việc sử dụng SELECT * không phải lúc nào cũng xấu. Thực tế, bạn có thể chấp nhận đánh đổi chi phí để lấy sự tiện lợi. Ví dụ, khi bạn cần tạo các bảng tổng hợp (datamart) chứa nhiều dữ liệu cho nhiều mục đích phân tích khác nhau, SELECT * vẫn được chấp nhận. Dần dần, khi đã làm quen với cách kiểm soát chi phí, bạn có thể linh hoạt sử dụng SELECT * trong những trường hợp thật sự cần thiết và hữu ích. Ngược lại, khi sử dụng để lên các báo cáo, gần như bạn không cần dùng tới SELECT *.
Tạo thành bảng cứng để tiết kiệm chi phí so với view
View là một bảng ảo, khi bạn truy vấn một view, BigQuery sẽ chạy lại toàn bộ câu lệnh SQL tạo ra nó. Điều này có thể tốn kém và tốn thời gian nếu view đó phức tạp.
Ngược lại, bảng cứng (materialized table) là một bảng thực tế chứa dữ liệu đã được tính toán sẵn. Khi bạn truy vấn một bảng cứng, BigQuery chỉ cần đọc dữ liệu từ bảng đó, không cần tính toán lại từ đầu, giúp truy vấn nhanh hơn rất nhiều. BigQuery đối xử với các "materialize view" này chính là các native table (các bảng dữ liệu hoàn chỉnh).
Một ưu điểm lớn nữa là bạn có thể tạo partition cho bảng cứng, điều mà view không hỗ trợ. Điều này giúp tối ưu hóa hơn nữa chi phí và tốc độ truy vấn. Bạn có thể sử dụng các công cụ như tính năng transformation của Elton hoặc schedule query của BigQuery để tự động tạo và cập nhật bảng cứng.
Bảng cứng có thể làm "nền" để bạn viết tiếp các câu truy vấn phức tạp hơn, giúp chuỗi xử lý dữ liệu của bạn trở nên hiệu quả và gọn gàng hơn.
Ví dụ: Trong dataset sales_datamart, bạn có thể tạo bảng sales_all_orders chứa tất cả dữ liệu đơn hàng từ trước đến nay. Bảng này được tạo ra bằng một câu SELECT từ bảng sales_orders, nối với bảng product để lấy thông tin sản phẩm, nối với product_category để lấy thông tin ngành hàng, nối với bảng users để biết nhân viên bán hàng là ai, và nối với bảng stock_in_out để biết tình hình xuất nhập kho của từng số serial sản phẩm.
Việc sử dụng bảng sales_all_orders (được partition theo cột sales_date) để lên báo cáo sẽ nhanh, tiết kiệm và dễ dàng hơn. Đặc biệt với các thao tác kéo thả trên các công cụ như PowerBI, Looker Studio, Tableau... sẽ trở nên hiệu quả hơn nhiều về mặt chi phí và tốc độ.
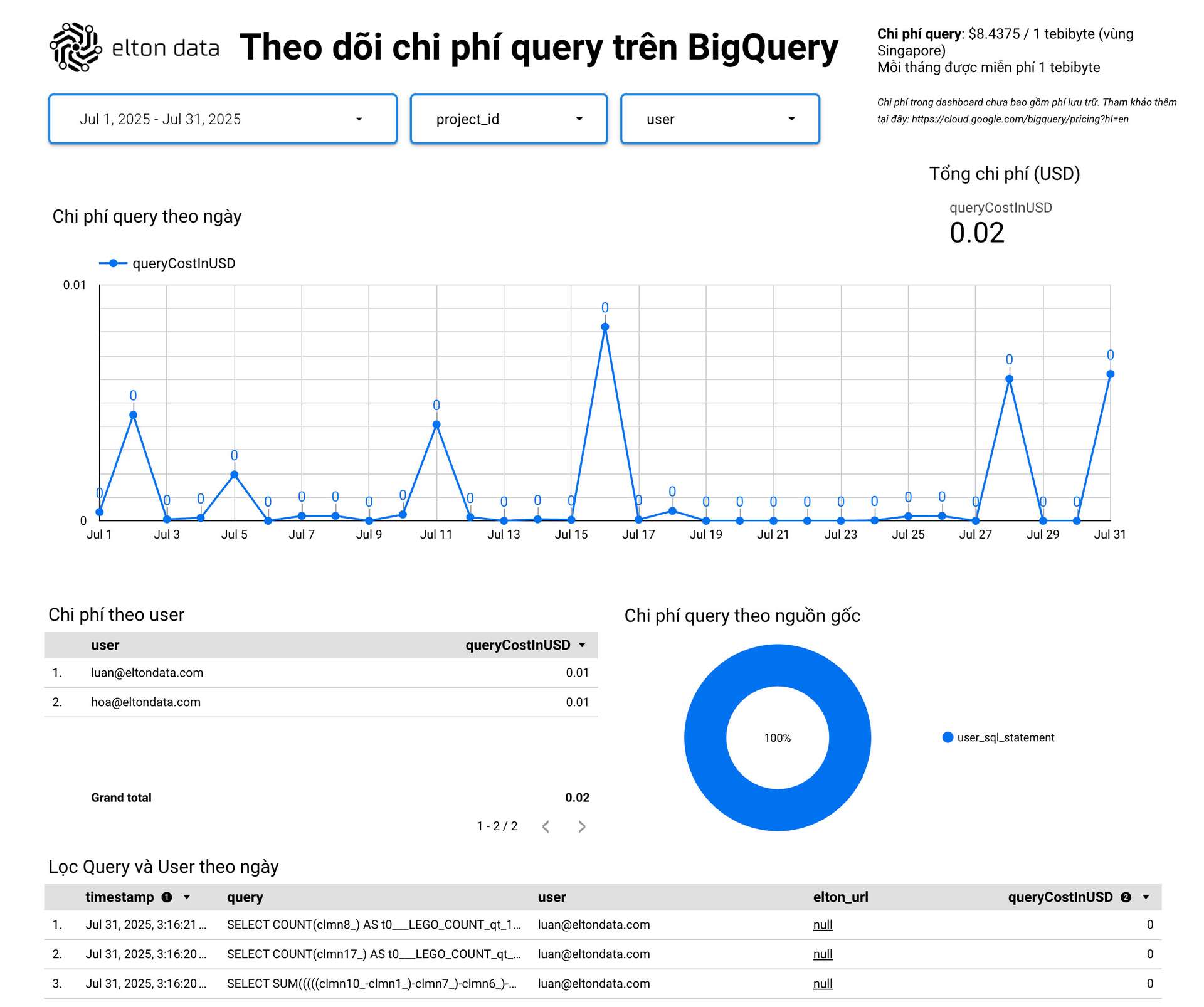
Giám sát chi phí sử dụng thường xuyên
Việc theo dõi chi phí sử dụng BigQuery một cách thường xuyên là rất quan trọng để tránh các chi phí phát sinh ngoài ý muốn. BigQuery cung cấp các công cụ để bạn có thể xem chi tiết chi phí của từng câu truy vấn.
Elton cũng có cung cấp dashboard template giúp bạn theo dõi từng câu SQL được thực thi trên BigQuery. Dựa vào đó, bạn có thể dễ dàng nhận ra những câu truy vấn nào chạy nhiều và tốn nhiều chi phí nhất để có thể tập trung tối ưu chúng. Một số điểm bạn có thể lưu ý khi giám sát:
- Xem các câu SQL nào đang không dùng partition và cân nhắc chuyển sang dùng partition.
- Kiểm tra các câu SQL trùng lặp giữa các báo cáo. Nếu có thể, nên quy về dùng chung một bảng hoặc một data model để tối ưu.
- Kiểm tra tần suất sử dụng và phát sinh SQL xem có gì bất thường không.
Một số cách mình hay dùng để viết SQL gọn hơn
Ngoài những cách trên, việc viết SQL sao cho dễ đọc, dễ bảo trì cũng là một yếu tố quan trọng giúp tối ưu công việc.
- Sử dụng CTE (Common Table Expressions) thay vì nested query: CTE giúp bạn chia một câu lệnh SQL phức tạp thành nhiều phần nhỏ, dễ hiểu. Thay vì viết những câu subquery lồng nhau (nested query) khó đọc, bạn có thể dùng WITH để định nghĩa các bảng tạm, làm cho câu truy vấn trở nên rõ ràng và có cấu trúc hơn.
- Nếu tool BI của bạn hỗ trợ nested object, hãy dùng nó để đỡ viết câu query UNNEST: Nested object (đối tượng lồng) là một cấu trúc dữ liệu cho phép bạn lưu trữ các bản ghi lặp lại trong một cột duy nhất. Khi làm việc với dữ liệu lồng, bạn thường phải dùng câu lệnh UNNEST để "mở" các mảng này ra. Tuy nhiên, nếu công cụ BI của bạn có hỗ trợ, hãy tận dụng nó để truy cập trực tiếp vào dữ liệu lồng mà không cần viết các câu UNNEST phức tạp, giúp câu query của bạn trở nên gọn gàng hơn.
- Viết hoa các từ khóa: Việc viết hoa các từ khóa của SQL như SELECT, FROM, WHERE, COUNT, SUM... giúp câu lệnh dễ đọc và dễ phân biệt với tên bảng hay tên cột hơn.
- Viết câu vừa đủ: Tránh viết một câu SQL quá dài và khó xem, đặc biệt là khi làm việc trên màn hình nhỏ. Bạn nên ngắt câu, đặt các thành phần ở những dòng khác nhau để câu lệnh có cấu trúc rõ ràng.
- Đặt tên có ý nghĩa: Hãy đặt tên cho bảng, cột và các đối tượng khác có ý nghĩa, dễ hiểu. Thà rằng tên hơi dài một chút còn hơn là viết tắt mà không ai hiểu.
Ví dụ một câu query mình sử dụng các điều trên:
1WITH flatten_invoice_lines AS (
2 SELECT
3 invoice_id,
4 STRUCT(
5 CAST(JSON_VALUE(details, '$.productId') AS INT64) AS product_id,
6 JSON_VALUE(details, '$.productCode') AS product_code,
7 JSON_VALUE(details, '$.productName') AS product_name,
8 CAST(JSON_VALUE(details, '$.categoryId') AS INT64) AS category_id,
9 JSON_VALUE(details, '$.categoryName') AS category_name,
10 CAST(JSON_VALUE(details, '$.quantity') AS INT64) AS quantity,
11 CAST(JSON_VALUE(details, '$.price') AS FLOAT64) AS price,
12 CAST(JSON_VALUE(details, '$.discount') AS FLOAT64) AS discount,
13 CAST(JSON_VALUE(details, '$.usePoint') AS BOOLEAN) AS use_point,
14 CAST(JSON_VALUE(details, '$.subTotal') AS FLOAT64) AS sub_total,
15 JSON_VALUE(details, '$.serialNumbers') AS serial_numbers,
16 CAST(JSON_VALUE(details, '$.returnQuantity') AS INT64) AS return_quantity
17 ) AS product_details
18 FROM `elton-data-project.kiotviet_dwh.kiotviet_invoice` invoice
19 , UNNEST(invoice_details) AS details
20),
21invoice_lines_array AS (
22 SELECT
23 invoice_id,
24 ARRAY_AGG(product_details) AS invoice_items
25 FROM flatten_invoice_lines
26 GROUP BY invoice_id
27),
28flatten_invoice_delivery AS (
29 SELECT
30 invoice_id,
31 JSON_VALUE(invoice_delivery, '$.deliveryCode') AS delivery_code,
32 JSON_VALUE(invoice_delivery, '$.serviceType') AS service_type,
33 JSON_VALUE(invoice_delivery, '$.serviceTypeText') AS service_type_text,
34 CAST(JSON_VALUE(invoice_delivery, '$.status') AS INT64) AS delivery_status,
35 JSON_VALUE(invoice_delivery, '$.statusValue') AS delivery_status_value,
36 JSON_VALUE(invoice_delivery, '$.receiver') AS receiver,
37 JSON_VALUE(invoice_delivery, '$.contactNumber') AS contact_number,
38 JSON_VALUE(invoice_delivery, '$.address') AS address,
39 CAST(JSON_VALUE(invoice_delivery, '$.usingPriceCod') AS BOOLEAN) AS using_price_cod,
40 CAST(JSON_VALUE(invoice_delivery, '$.partnerDeliveryId') AS INT64) AS partner_delivery_id,
41 JSON_VALUE(invoice_delivery, '$.partnerDelivery.code') AS partner_delivery_code,
42 JSON_VALUE(invoice_delivery, '$.partnerDelivery.name') AS partner_delivery_name,
43 CAST(JSON_VALUE(invoice_delivery, '$.latestStatus') AS INT64) AS latest_status
44 FROM `elton-data-project.kiotviet_dwh.kiotviet_invoice`
45),
46flatten_invoice_payments AS (
47 SELECT
48 invoice_id,
49 STRUCT(
50 CAST(JSON_VALUE(payments, '$.id') AS INT64) AS id,
51 JSON_VALUE(payments, '$.code') AS code,
52 CAST(JSON_VALUE(payments, '$.amount') AS FLOAT64) AS amount,
53 JSON_VALUE(payments, '$.description') AS description,
54 JSON_VALUE(payments, '$.method') AS method,
55 CAST(JSON_VALUE(payments, '$.status') AS INT64) AS invoice_payment_status,
56 JSON_VALUE(payments, '$.statusValue') AS invoice_payment_status_value,
57 JSON_VALUE(payments, '$.transDate') AS trans_date
58 ) AS payment_details
59 FROM `elton-data-project.kiotviet_dwh.kiotviet_invoice`
60 , UNNEST(payments) AS payments
61),
62invoice_payments_array AS (
63 SELECT
64 invoice_id,
65 ARRAY_AGG(payment_details) AS invoice_payments
66 FROM flatten_invoice_payments
67 GROUP BY invoice_id
68)
69SELECT
70 -- Main invoice data
71 invoice.* EXCEPT (invoice_details, payments, invoice_order_surcharges),
72
73 -- Sale channel information
74 sc.name AS sale_channel_name,
75
76 -- Invoice items array
77 ila.invoice_items,
78
79 -- Delivery information
80 fid.* EXCEPT (invoice_id),
81
82 -- Payment information
83 ipa.invoice_payments
84
85FROM `elton-data-project.kiotviet_dwh.kiotviet_invoice` invoice
86LEFT JOIN `elton-data-project.kiotviet_dwh.kiotviet_sale_channel` sc ON sc.sale_channel_id = invoice.sale_channel_id
87LEFT JOIN invoice_lines_array ila ON ila.invoice_id = invoice.invoice_id
88LEFT JOIN flatten_invoice_delivery fid ON fid.invoice_id = invoice.invoice_id
89LEFT JOIN invoice_payments_array ipa ON ipa.invoice_id = invoice.invoice_id