
Hiện tại nhu cầu query trên MongoDB càng lúc càng nhiều. Ở vị trí của một thằng Data Engineer thì mình có lợi thế là có nguyên một cái data pipeline đồ sộ để rút mọi thể loại data về Data Warehouse (dùng Google BigQuery) nên mình luôn ưu tiên dùng cách này. Lên BigQuery thì cái gì mà chả dùng SQL được, SQL tẹt ga đủ đồ chơi của bộ chuẩn ANSI, kể cả JSON file hay data từ NoSQL.

Sơ lược về nhu cầu
Nhưng nhược điểm của nó là làm cho mọi chuyện phức tạp hơn vì data sẽ phải đi qua một bộ normalizer do mình viết. Bộ normalizer này có tác dụng đảm bảo field lấy từ các NoSQL database sẽ được giữ scheme và data type ổn định trước khi đi vào pipeline của mình và load lên warehouse.
Mình sẽ nói về quy trình load data từ các RDMBS và NoSQL DB lên BigQuery trong một bài viết khác, trong bài này giải quyết vấn đề như tiêu đề trước đã.
Vậy phải làm sao khi bạn chỉ đơn giản cần query MongoDB bằng SQL? Mình đi Google nhiều giải pháp khác nhau, và nhanh nhất, rẻ nhất là dùng Apache Drill.
Drill được phát triển lấy cảm hứng từ Dremel, cũng là engine bên dưới của BigQuery, nó sẽ connect đến các data source NoSQL như CSV, JSON file, HDFS, Hive, file lưu trên S3 và đương nhiên là cả MongoDB nữa. Nó còn có thể query cross data source, tức là bạn lấy data của MongoDB join với file CSV hay JSON từ server và join thêm với data trong MySQL cũng được.

Drill có bộ phận chính để query là Drill Bit, nó mở qua port 31310, ngoài ra còn có một UI để viết, quản lý query job nữa. Drill có thể chạy cluster hoặc single node tùy ý bạn, nhờ vậy bạn có thể cài Drill lên chiếc laptop của mình để bắt đầu khám phá dữ liệu, hoặc cài lên server để cả team cùng bay vào query chung.
Chạy thử
Để bắt đầu với Drill thì bạn có thể follow theo guide này: https://drill.apache.org/blog/2014/11/19/sql-on-mongodb/ cực kì dễ hiểu. Mình cũng làm theo y chang, chỉ khác là mình dùng Drill thông qua docker (mình lười mà):
docker run -i — name drill-1.14.0 -p 8047:8047 — detach -t drill/apache-drill:1.14.0 /bin/bash
Chỉ cần 1 dòng là Drill đã sẵn sàng cho bạn nghịch.
Giờ vào phần chính: Drillbit, nó là nơi Drill giao tiếp với thế giới. Một giao diện xinh xinh dễ thương được viết bằng Bootstrap, nó nằm ở http://localhost:8047/query
Cứ theo hướng dẫn ở trên để activate MongoDB Storage Plugin cho Drill là được. Sẵn sàng chiến.
Thử ngay nè:
Xem thử các datasource đang có:
SHOW SCHEMAS;
Query thử một phát:
select city, COUNT(DISTINCT nid) AS number_of_shops
from mongo.app.shops
group by city
Kết quả:
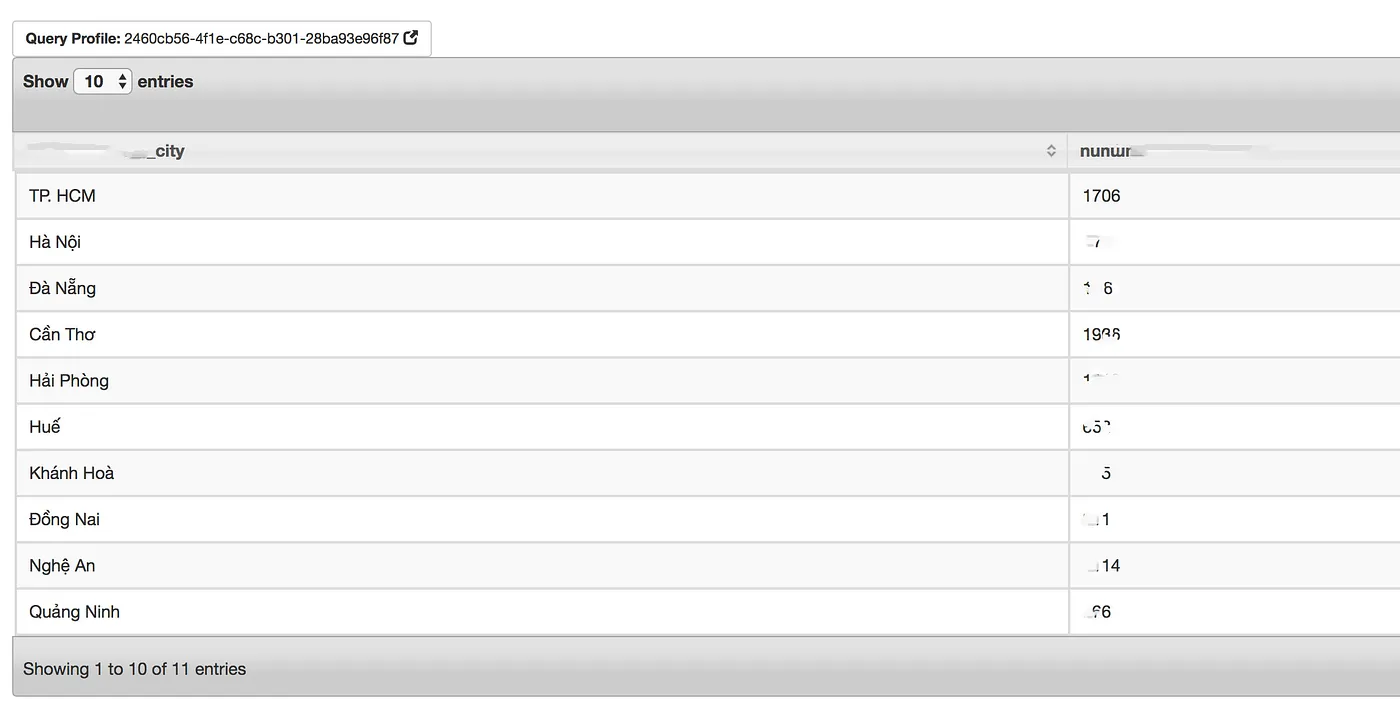
Query chạy khá nhanh, tất nhiên không nhanh như khi bạn chạy trực tiếp trên RDBMS rồi nhưng vẫn ổn cho nhu cầu analytics.
Sau khi query được bằng SQL thì bạn có thể connect các tool BI của bạn vào Drill để query. Ví dụ như Tableau hay Redash chẳng hạn. Drill hỗ trợ JDBC mà nên tẹt ga thôi, coi như bao cái SQL data source khác.
Update: Vừa query thêm một câu phức tạp với 2 cái CTE, Drill chạy khá ổn trên laptop với dataset vừa vừa cỡ gần trăm nghìn dòng, thực hiện nhiều operation phức tạp như MAX, sau đó flat các nested object trong MongoDB ra
WITH latest_record AS (
SELECT m.x, CAST(m._timestamp AS DATE) AS date_recorded, MAX(m._timestamp) AS latest_timestamp
FROM mongo.x.y m
GROUP by m.x, CAST(m._timestamp AS DATE)
),
flat_table AS (
SELECT latest_record.*, m.*, FLATTEN(m.products) AS products
FROM latest_record
JOIN mongo.x.y m
ON m.x = latest_record.x
AND m._timestamp = latest_record.latest_timestamp
)
SELECT flat_table.*, flat_table.products.price AS price, flat_table.products.item AS quantity
FROM flat_table
Drill hay chỗ nào
Mỗi Drill bit có thể chạy trên từng node của hệ thống data, nên nó có thể lấy data nhanh hơn. Bạn không cần phải cài Drill lên hết mọi node, nhưng nếu cài thì processing power sẽ được đẩy về cho các node nơi chứa data thay vì phải gom hết tập trung về một nơi trước khi được xử lý, lọc (WHERE) hay tính toán. Cái này gọi là Locality
Drill cũng hay ở chỗ nó tận dụng tối đa các columnar format, ví dụ như AVRO hay Parquet. Ví dụ bạn chạy query như sau:
SELECT COUNT(store_id) FROM stores
thì Drill sẽ chạy scan cột store_id của các file mà thôi nên sẽ đạt performance cao, không như việc phải scan hết cả row cho mọi file. Ngoài ra mọi thao tác tính toán của Drill đều chạy trên columnar format hết nên nó không cần convert qua định dạng trung gian nào, tiết kiệm nhiều thời gian.
Cơ chế này y chang như PrestoDB, vốn là nền của AWS Athena, hoặc BigQuery khi bạn query file chứa trên S3 và Google Cloud Storage. Khá là hay.
Với khả năng query trên MongoDB, mình chưa tìm hiểu xem nó chạy như nào. Bạn nào biết thì hãy chia sẻ với mình nhé. Tạm thời thì thấy nó works với lại lo làm việc cái đã rồi tính sau :D
Tạm thời test nhiêu đây đã, có gì hay share kĩ hơn sau nha :D Trước mắt Drill giảm workload cho mình khá nhiều, cũng như hỗ trợ team phân tích một vài thứ nhanh chóng, đơn giản ngay trên MongoDB mà không cần load data về warehouse.